The Need for Speed
Not the game, or the movie. Rather, a way to describe how jumping back into studies with my third studio unit feels. The title is also quite fitting given our first task, optimisation of a rudimentary ray tracer in C++. The ray tracer has been written to be as accurate as possible with easily readable code and a straightforward structure, with no efforts made performance wise. Our brief is quite literally to make the ray tracer run as fast as possible however we see fit. Each peer is required to complete the task as they will be compared for not only performance, but the ability to retain accuracy in its output.
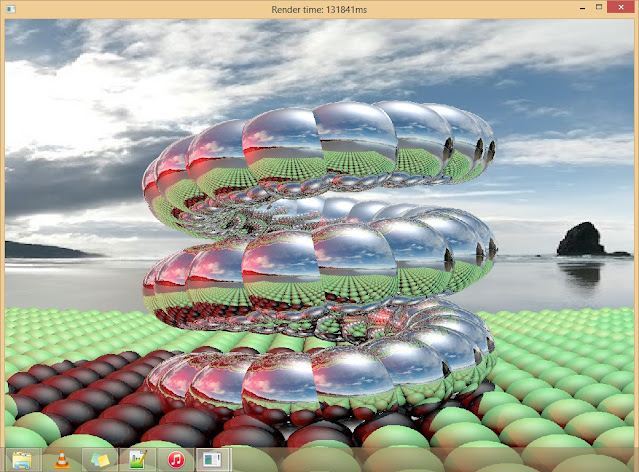
The image below shows the original build after running on my i3 laptop with a rendering time of over 2 minutes. During our first lecture, a great focus was placed the topics of parallel and cache aware programming. This is an interesting area for me having not written multithreaded programs before. However I decided to implement spatial partitioning before making any optimisations using those techniques. Tree structures I considered were bounding volume hierarchies (BVH) and Octrees. I chose Octrees having already written a BVH in the past, I also felt it a more suitable choice given the layout of the scene.
I started by writing a simple Axis Aligned Bounding Box (AABB) class that would provide the backbones for the Octree structure. My AABB class includes functions to define and merge bounding regions, alongside methods to check for intersections with objects such as spheres. The Octree class itself is a simple container with a root node and functions for subdividing and traversing the node hierarchy until a leaf node is found. Nodes are nothing more than a struct of pointers to their parent, children or renderable entities if they are a leaf node and an AABB. Octree traversal was kept fairly primitive and works using a queuing system.
I'm not sure if this is a good method of implementation or not, as I wanted to challenge myself by seeing if I could develop a working system without following any tutorials and such. The way I traverse the Octree is by looping over a queue of nodes, initially consisting of only the root node until the queue is empty. On each node iteration before the node is removed from the queue, an intersection test with the ray is performed on each child node and added to the queue if hit, to have their children eventually checked and so forth. Once a leaf node is reached, it is added to an array of potentially visible leaves that are returned once traversal is complete.

In the image above, the results of rendering with the Octree are shown without depth sorting of any kind. The idea is to sort the list of potentially visible leaves by distance from the ray origin, check each of its renderable entities in that order and stop once an object or sphere in this case is hit. I found that it was faster to avoid sorting the leaves for the purposes of occlusion culling, since each recorded hit between the ray and a sphere is already being checked by distance. Iterating through all of the spheres in each leaf node proved to be substantially faster than an expensive sort operation, given that the overall number of objects checked per ray was still dramatically less than before.
The next step in optimisation that I took was going through the entire render loop and all of the functions that are subsequently called. I removed all traces of division and modulus operations by replacing them with their multiplicative equivalent, in some cases this meant calculating the inverse of a value which I would precompute where possible and cache in a new variable. Any simple loops with few iterations were unrolled or reversed and nested loops combined, such as the main render loop. Finally, any commonly used nested member pointers were cached in a new pointer directly. This optimisation alone shaved quite a few seconds more off the overall render time than I had expected.

Finally the last step was the use of OpenMP to have the ray tracer perform in parallel. I chose to parallelise the main render loop and the final intersection tests on the leaf nodes and objects. By default, parallelisation of the nested render loop would split the work in horizontal chunks. I found after combining the loops for each axis, that rendering in a vertical fashion enormously reduced the number of cache misses. The image above was taken halfway through rendering in its final form, with the main vertical favoured loop clearly divided among each of my 4 logical cores.
The rendering time overall now averages around 13 seconds, quite an improvement from the original 2 minutes and 11 seconds. Spatial partitioning on its own reduced the rendering time by around 70%, with OpenMP further cutting the render time in half before all other optimisations. Although not necessary for the point of this exercise, it would be easily possible to spend days restructuring the layout of data to further avoid potentially expensive cache misses. I am curious to see how it runs on different, faster systems with more cores and what other peers have managed to achieve.
The image below shows the original build after running on my i3 laptop with a rendering time of over 2 minutes. During our first lecture, a great focus was placed the topics of parallel and cache aware programming. This is an interesting area for me having not written multithreaded programs before. However I decided to implement spatial partitioning before making any optimisations using those techniques. Tree structures I considered were bounding volume hierarchies (BVH) and Octrees. I chose Octrees having already written a BVH in the past, I also felt it a more suitable choice given the layout of the scene.

I started by writing a simple Axis Aligned Bounding Box (AABB) class that would provide the backbones for the Octree structure. My AABB class includes functions to define and merge bounding regions, alongside methods to check for intersections with objects such as spheres. The Octree class itself is a simple container with a root node and functions for subdividing and traversing the node hierarchy until a leaf node is found. Nodes are nothing more than a struct of pointers to their parent, children or renderable entities if they are a leaf node and an AABB. Octree traversal was kept fairly primitive and works using a queuing system.
I'm not sure if this is a good method of implementation or not, as I wanted to challenge myself by seeing if I could develop a working system without following any tutorials and such. The way I traverse the Octree is by looping over a queue of nodes, initially consisting of only the root node until the queue is empty. On each node iteration before the node is removed from the queue, an intersection test with the ray is performed on each child node and added to the queue if hit, to have their children eventually checked and so forth. Once a leaf node is reached, it is added to an array of potentially visible leaves that are returned once traversal is complete.

In the image above, the results of rendering with the Octree are shown without depth sorting of any kind. The idea is to sort the list of potentially visible leaves by distance from the ray origin, check each of its renderable entities in that order and stop once an object or sphere in this case is hit. I found that it was faster to avoid sorting the leaves for the purposes of occlusion culling, since each recorded hit between the ray and a sphere is already being checked by distance. Iterating through all of the spheres in each leaf node proved to be substantially faster than an expensive sort operation, given that the overall number of objects checked per ray was still dramatically less than before.
The next step in optimisation that I took was going through the entire render loop and all of the functions that are subsequently called. I removed all traces of division and modulus operations by replacing them with their multiplicative equivalent, in some cases this meant calculating the inverse of a value which I would precompute where possible and cache in a new variable. Any simple loops with few iterations were unrolled or reversed and nested loops combined, such as the main render loop. Finally, any commonly used nested member pointers were cached in a new pointer directly. This optimisation alone shaved quite a few seconds more off the overall render time than I had expected.

Finally the last step was the use of OpenMP to have the ray tracer perform in parallel. I chose to parallelise the main render loop and the final intersection tests on the leaf nodes and objects. By default, parallelisation of the nested render loop would split the work in horizontal chunks. I found after combining the loops for each axis, that rendering in a vertical fashion enormously reduced the number of cache misses. The image above was taken halfway through rendering in its final form, with the main vertical favoured loop clearly divided among each of my 4 logical cores.
The rendering time overall now averages around 13 seconds, quite an improvement from the original 2 minutes and 11 seconds. Spatial partitioning on its own reduced the rendering time by around 70%, with OpenMP further cutting the render time in half before all other optimisations. Although not necessary for the point of this exercise, it would be easily possible to spend days restructuring the layout of data to further avoid potentially expensive cache misses. I am curious to see how it runs on different, faster systems with more cores and what other peers have managed to achieve.


Comments
Post a Comment